- Autor: Christian Radny
- Veröffentlicht: 10.06.2023
- Kategorie: SEO
Ja, ich benutze Noindex zusammen mit Canonical-Links
Transkription meines YouTube-Videos.

Quelle: https://www.youtube.com/watch?v=EPtGglkZ2N8
Inhaltsverzeichnis
- 0:00 - Einleitung
- 0:22 - Duplicate Content Problem
- 0:44 - Duplicate Content vermeiden
- 1:26 - Für mich hat nicht funktioniert
- 2:03 - John Mueller über Noindex mit Canonical-Links
- 3:10 - Warum ist ein Canonical-Link wichtig?
- 4:36 - Warum verwenden viele SEOs Noindex niemals mit einem Canonical-Link?
- 4:58 - Schlusswort
Einleitung
Wusstet ihr schon, dass ihr Noindex zusammen mit Canonical-Links verwenden könnt? Und ich meine damit keinen selbstreferenzierenden Canonical-Link, sondern einen Canonical-Link, der auf eine indexierte Seite verweist.
John Müller von Google hat sich diesbezüglich geäußert. Aber dazu später mehr. Ich erkläre zuerst das Problem.
Duplicate Content Problem
Angenommen, ihr habt eine Kategorieseite im Onlineshop, die alphabetisch nach Produktnamen sortiert werden kann. Die Sortierung ist aufrufbar über angehängte Parameter an die URL der Kategorieseite.

Quelle: https://www.flaggenplatz.de/tischflaggen/?order=name&dir=asc
Dies ist ein klassischer Fall von Duplicate Content, wenn beide URLs von Google indexiert werden. Duplicate Content ist schlecht fürs Ranking und muss vermieden werden.
Duplicate Content vermeiden
Ihr habt folgende Möglichkeiten, um Duplicate Content zu vermeiden:
- Ihr lasst beide URLs indexieren, und Google soll selbst einen Canonical-Link finden. Kann klappen, muss aber nicht.
- Ihr setzt einen Canonical-Link auf die Kategorieseite ohne URL-Parameter.
- Ihr kennzeichnet alle URL-Parameter Seiten mit Noindex.
- Ihr verbietet das Crawlen von URL-Parametern per robots.txt.
- Ihr kennzeichnet alle URL-Parameter Seiten mit Noindex und setzt zusätzlich einen Canonical-Link auf die URL ohne Parameter.
Für mich hat nicht funktioniert
Ich habe alle fünf Möglichkeiten fast 2 Jahre getestet. Für mich hat nicht funktioniert:
- Nichts einstellen und Google selbst entscheiden lassen. Dies führte zu vielen unerwünschten Seiten im Index.
- Crawling-Verbot der URL-Parameter per robots.txt. Trotz Verbots landeten viele URLs mit Parametern ohne Inhalt im Index. Das passiert, wenn es irgendwo Links zu diesen Seiten gibt, und Google denkt, dass es sich um wichtige URLs handelt. Leider habe ich es nicht geschafft, sämtliche Links zu entfernen, deshalb habe ich diese Möglichkeit komplett verworfen, und mich auf die verbleibenden drei Möglichkeiten konzentriert.
John Mueller über Noindex mit Canonical-Links
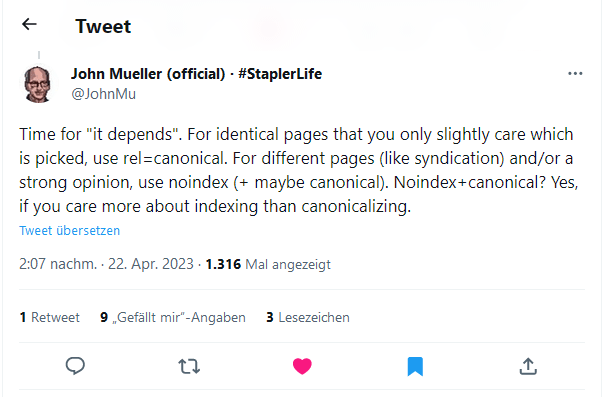
Ich komme zurück auf die Äußerung von John Müller über die Verwendung von Noindex zusammen mit einem Canonical-Link.
Er schreibt auf Twitter:
Für eine identische Seite ohne Präferenz, welche Seite von Google als kanonisch angesehen werden soll, lässt man beide Seiten indexieren und setzt einen Canonical-Link. Ein Beispiel hierfür ist eine statische HTML-Seite, die extern über eine Google Click ID verlinkt wird und dadurch im Index erscheint. Das passiert, weil ein Canonical-Link nur ein Hinweis für Google ist. Google folgt diesem Hinweis nicht immer. Meistens aber schon. In diesem Fall ist es aber unproblematisch, welche Seite im Index erscheint und als kanonisch angesehen wird, weil beide Seiten identisch sind.
John schreibt weiter:
Für unterschiedliche Seiten, wie Sortierungen in Kategorien, kann ein Noindex und eventuell ein Canonical-Link verwendet werden. In diesem Fall ist euch die Indexierung wichtiger als die Kanonisierung. Die Noindex Anweisung ist dann eine Art Fallback, wenn der Canonical-Link von Google nicht akzeptiert wird.
Warum ist ein Canonical-Link wichtig?
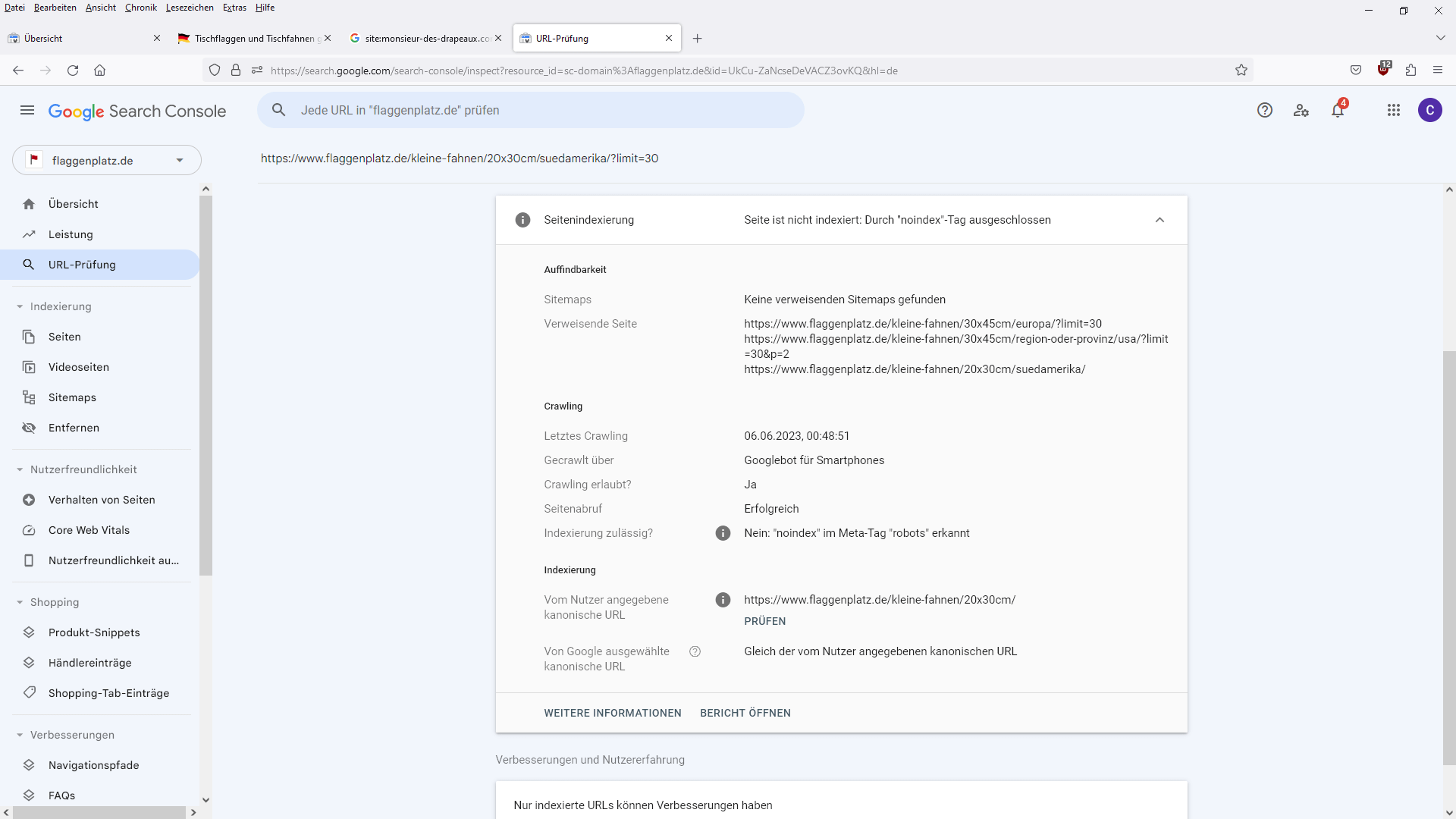
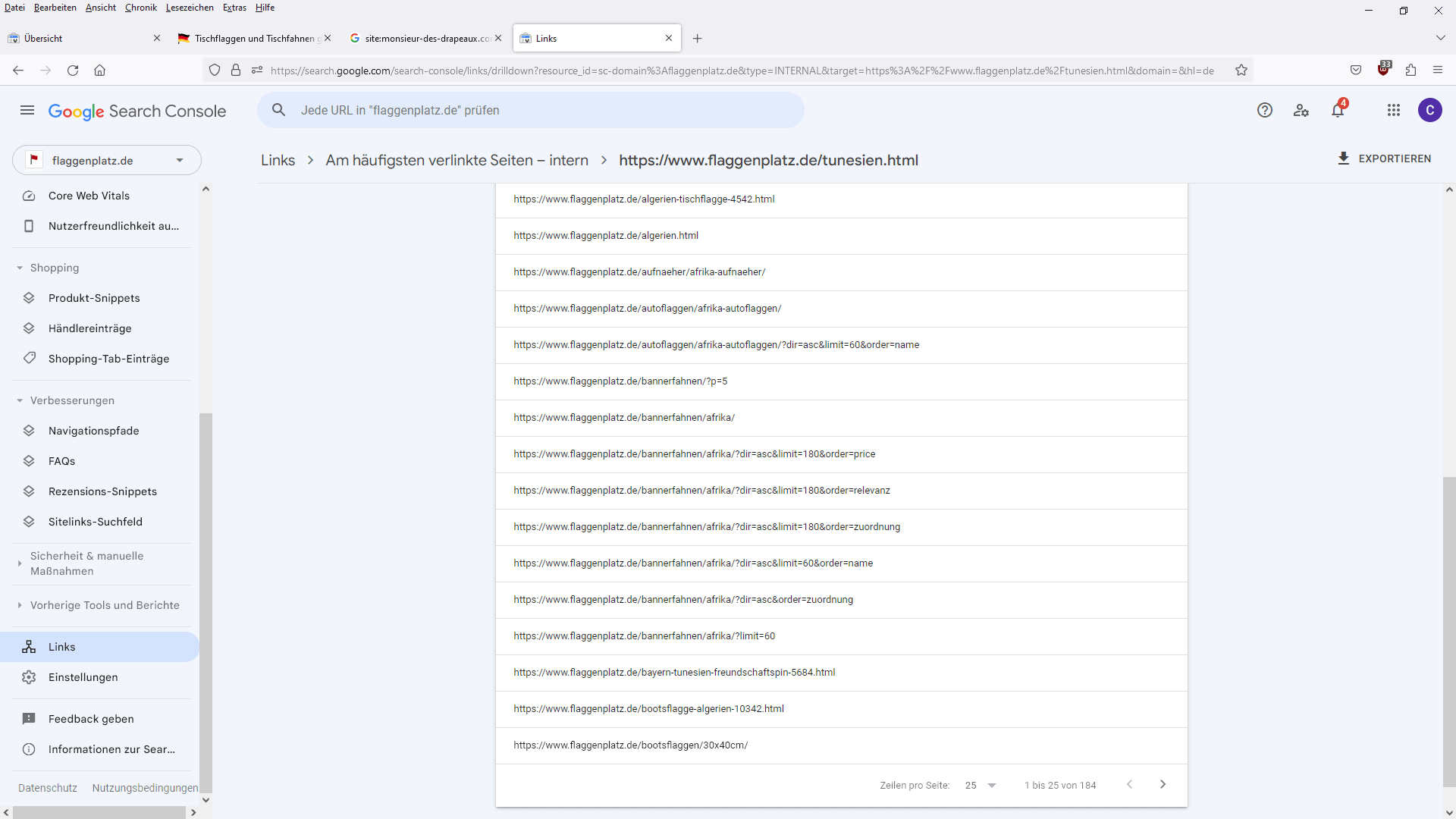
Google verarbeitet Links immer nur zwischen Canonical-URLs. Welche URL Google als Canonical benutzt, erfahrt ihr mit dem URL Inspector Tool in der Search Console. Ich habe John Müller diesbezüglich in einem Webmaster Sprechstunden Hangout befragt.
Wenn ihr eine URL mit Parametern nur auf Noindex setzt, dann kann es passieren, dass Links von dieser URL verarbeitet werden. Ob Links von bestimmten URLs verarbeitet werden, seht ihr im internen Links Bericht in der Search Console.
Warum kann das ein Problem sein?
Es ist nicht direkt ein Problem, aber ich konzentriere gerne alle Signale so gut wie möglich.
Ich nehme nochmals das Beispiel von der alphabetischen Sortierung einer Kategorieseite. Wenn man alle URLs mit Parametern mit Noindex kennzeichnet, einen Canonical-Link zur Kategorieseite ohne Parameter setzt und dieser auch tatsächlich akzeptiert wird, dann konzentrieren sich alle Signale in der Kategorieseite ohne Parameter.
Google crawlt diese URL häufiger, eventuelle externe Links werden der Kategorieseite ohne Parameter zugeordnet und die Links zu den Produkten erscheinen nicht mehr auf weiteren URLs. Strukturell gesehen, kann dies nur Vorteile haben.
Warum verwenden viele SEOs Noindex niemals mit einem Canonical-Link?
Diese SEOs nehmen an, dass eine Noindex Anweisung weitergereicht wird und damit beide Seiten aus dem Index entfernt, weil es sich ja um identische Seiten handeln soll.
Eine andere These besagt, dass Google die Noindex Anweisung als Fehler wertet, und beide Seiten indexiert.
Schlusswort
Probiert es am besten selbst aus und bewertet eure Tests anhand der Daten in der Search Console. Ihr findet akzeptierte Canonical-Links auf euren Noindex Seiten im Bericht zur Seitenindexierung – Durch “noindex”-Tag ausgeschlossen.
Schaut bitte auch unten in die Video-Beschreibung. Dort findet ihr ein paar Links zum Thema.
Wenn ihr Fragen habt, dann schreibt sie bitte in die Kommentare zu diesem Video. Ansonsten könnt ihr mich auch gerne bei Twitter anhauen.
Viel Spaß beim Optimieren und wenn euch dieses Video gefallen hat, Daumen hoch und Kanal abonnieren.
Tschüssi …